(本文基于UNIX网络编程、官方文档及十数篇文档整理而成)
IO 多路复用接口
“多路”是指多个网络连接,“复用”是指一个线程。全称是一个线程去处理多个网络连接。这种方式可以减少服务端线程的上下文切换,支持大并发的请求。
select
select函数允许进程指示内核等待多个事件中的任何一个发生,并只在有一个或多个事件发生或经历一段指定的时间后才唤醒它。
作为一个例子,我们可以调用select,告知内核仅在下列情况发生时才返回:
- 集合{1,4,5}中的任何描述符准备好读;
- 集合{2,7}中的任何描述符准备好写;
- 集合{1,4}中的任何描述符有异常条件待处理;
- 已经历了10.2秒。
原理概述
select采用是的轮询的方式,在Linux中一切皆文件,那么网络socket也属于文件的一种。首先将所有的文件描述符保存到fds[i]数组中。
- select()函数接收的参数为fd_set(底层是一个bitmap数组,底层默认大小为1024);
- 将fds[i]转化为fd_set集合;
- 将fd_set由用户态拷贝到内核态(内核判断哪个socket有数据),select是阻塞函数;
- 在内核会不断遍历fd_set,当某个socket有数据到来时,会将fd_set置位(即标识有数据到来,修改fd_set)并且select()返回;
- select()返回后,仍需遍历fd_set,判断哪个socket有数据到来;
select提高效率的最主要一点是:将fd_set放到了内核态,让内核去判断是否有socket返回数据。
程序执行select后,如果没有数据输入,程序会一直等待(阻塞时),直到有数据为止,也就是程序中无需循环和sleep。
每次调用select,都需要把fd_set集合从用户态拷贝到内核态,这个开销在fd_set很多时会很大同时每次调用select都需要在内核遍历传递进来的所有fd_set,这个开销在fd_set很多时也很大
select()
Linux manual page:select(2)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
SELECT(2) Linux Programmer's Manual SELECT(2)
NAME
select, pselect, FD_CLR, FD_ISSET, FD_SET, FD_ZERO - synchronous I/O
multiplexing
SYNOPSIS
/* According to POSIX.1-2001 */
#include <sys/select.h>
/* According to earlier standards */
#include <sys/time.h>
#include <sys/types.h>
#include <unistd.h>
int select(int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout);
void FD_CLR(int fd, fd_set *set);
int FD_ISSET(int fd, fd_set *set);
void FD_SET(int fd, fd_set *set);
void FD_ZERO(fd_set *set);
方法定义
#include <sys/select.h>
#include <sys/time.h>
int select(
int maxfdp1,
fd_set *readset,
fd_set *writeset,
fd_set *exceptset,
const struct timeval *timeout);
// 返回:若有就绪描述符则为其数目,若超时则为0,若出错则为-1
select并不会直接返回给用户就绪的描述符,而是返回了就绪的描述符集合,因此需要程序员进行判断。
fd_set
select()机制中提供一fd_set的数据结构,实际上是一个long类型的数组,每一个数组元素都能与一打开的文件句柄(不管是socket句柄,还是其他文件或命名管道或设备句柄)建立联系,建立联系的工作由程序员完成,当调用select()时,由内核根据IO状态修改fd_set的内容,由此来通知执行了select()的进程哪一socket或文件发生了可读或可写事件。
typedef long int __fd_mask;
/* It's easier to assume 8-bit bytes than to get CHAR_BIT. */
#define __NFDBITS (8 * (int) sizeof (__fd_mask))
#define __FDELT(d) ((d) / __NFDBITS)
#define __FDMASK(d) ((__fd_mask) 1 << ((d) % __NFDBITS))
/* fd_set for select and pselect. */
typedef struct
{
/* XPG4.2 requires this member name. Otherwise avoid the name
from the global namespace. */
#ifdef __USE_XOPEN
__fd_mask fds_bits[__FD_SETSIZE / __NFDBITS];
# define __FDS_BITS(set) ((set)->fds_bits)
#else
__fd_mask __fds_bits[__FD_SETSIZE / __NFDBITS];
# define __FDS_BITS(set) ((set)->__fds_bits)
#endif
} fd_set;
/* Maximum number of file descriptors in `fd_set'. */
#define FD_SETSIZE __FD_SETSIZE //__FD_SETSIZE等于1024
/* Access macros for `fd_set'. */
#define FD_SET(fd, fdsetp) __FD_SET (fd, fdsetp)
#define FD_CLR(fd, fdsetp) __FD_CLR (fd, fdsetp)
#define FD_ISSET(fd, fdsetp) __FD_ISSET (fd, fdsetp)
#define FD_ZERO(fdsetp) __FD_ZERO (fdsetp)
简化下来,可以改成 (来源:详解fd_set结构体)
typedef struct{
long int fds_bits[32];
}fd_set;
select使用描述符集,通常是一个整数数组,其中每个整数中的每一位对应一个描述符。举例来说,假设使用32位整数,那么该数组的第一个元素对应于描述符0~31,第二个元素对应于描述符32~63,依此类推。所有这些实现细节都与应用程序无关,它们隐藏在名为fd_set的数据类型和以下四个宏中
//初始化描述符集
void FD_ZERO(fd_set *fdset);
//将一个描述符添加到描述符集
void FD_SET(int fd, fd_set *fdset);
//将一个描述符从描述符集中删除
void FD_CLR(int fd, fd_set *fdset);
//检测指定的描述符是否有事件发生
int FD_ISSET(int fd, fd_set *fdset);
头文件<sys/select.h>中定义的FD_SETSIZE常值是数据类型fd_set中的描述符总数,其值通常是1024,不过很少有程序用到那么多的描述符。maxfdp1参数迫使我们计算出所关心的最大描述符并告知内核该值。以前面给出的打开描述符1、4和5的代码为例,其maxfdp1值就是6。是6而不是5的原因在于:我们指定的是描述符的个数而非最大值,而描述符是从0开始的。
存在这个参数(maxfdp1)以及计算其值的额外负担纯粹是为了效率原因。每个fd_set都有表示大量描述符(典型数量为1024)的空间,然而一个普通进程所用的数量却少得多。内核正是通过在进程与内核之间不复制描述符集中不必要的部分,从而不测试总为0的那些位来提高效率的。
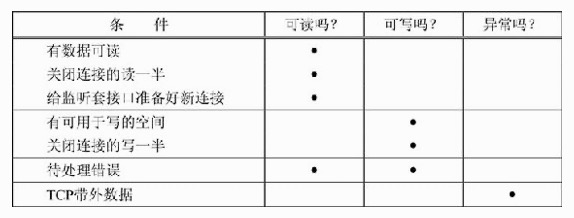
select就绪条件
读就绪
- socket内核中, 接收缓冲区中的字节数, 大于等于低水位标记SO_RCVLOWAT. 此时可以无阻塞的读该文件 描述符, 并且返回值大于0;
- socket TCP通信中, 对端关闭连接, 此时对该socket读, 则返回0;
- 监听的socket上有新的连接请求;
- socket上有未处理的错误;
写就绪
- socket内核中, 发送缓冲区中的可用字节数(发送缓冲区的空闲位置大小), 大于等于低水位标记 SO_SNDLOWAT, 此时可以无阻塞的写, 并且返回值大于0;
- socket的写操作被关闭(close或者shutdown). 对一个写操作被关闭的socket进行写操作, 会触发SIGPIPE 信号;
- socket使用非阻塞connect连接成功或失败之后;
- socket上有未读取的错误;
异常就绪
- socket上收到带外数据. 关于带外数据, 和TCP紧急模式相关(TCP协议头中, 有一个紧急指针的字段)
汇总了上述导致select返回某个套接字就绪的条件
例子
例子:检测 0、4、5 描述符是否准备好读
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
while(1)
{
fd_set rset;//创建一个描述符集rset
FD_ZERO(&rset);//对描述符集rset清零
FD_SET(0, &rset);//将描述符0加入到描述符集rset中
FD_SET(4, &rset);//将描述符4加入到描述符集rset中
FD_SET(5, &rset);//将描述符5加入到描述符集rset中
if(select(5+1, &rset, NULL, NULL, NULL) > 0)
{
if(FD_ISSET(0, &rset))
{
//描述符0可读及相应的处理代码
}
if(FD_ISSET(4, &rset))
{
//描述符4可读及相应的处理代码
}
if(FD_ISSET(5, &rset))
{
//描述符5可读及相应的处理代码
}
}
}
Linux manual page 示例,监听5秒内,0描述符是否有数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
#include <stdlib.h>
#include <sys/select.h>
int
main(void)
{
fd_set rfds;
struct timeval tv;
int retval;
/* Watch stdin (fd 0) to see when it has input. */
FD_ZERO(&rfds);
FD_SET(0, &rfds);
/* Wait up to five seconds. */
tv.tv_sec = 5;
tv.tv_usec = 0;
retval = select(1, &rfds, NULL, NULL, &tv);
/* Don't rely on the value of tv now! */
if (retval == -1)
perror("select()");
else if (retval)
printf("Data is available now.\n");
/* FD_ISSET(0, &rfds) will be true. */
else
printf("No data within five seconds.\n");
exit(EXIT_SUCCESS);
}
select 问题
select 的问题
- 监听的文件描述符有上限 FD_SETSIZE,一般是 1024。因为 fd_set 是个 bitmap,它为最多 nfds 个描述符都用一个 bit 去表示是否监听,即使相应位置的描述符不需要监听在 fd_set 里也有它的 bit 存在。nfds 用于创建这个 bitmap 所以 fd_set 是有限大小的。
- 在用户侧,select 返回后它并不是只返回处于 ready 状态的描述符,而是会返回传入的所有的描述符列表集合,包括 ready 的和非 ready 的描述符,用户侧需要去遍历所有 readfds、writefds、exceptfds 去看哪个描述符是 ready 状态,再做接下来的处理。还要清理这个 ready 状态,做完 IO 操作后再塞给 select 准备执行下一轮 IO 操作。
- 在 Kernel 侧,select 执行后每次都要陷入内核遍历三个描述符集合数组为文件描述符注册监听,即在描述符指向的 Socket 或文件等上面设置处理函数,从而在文件 ready 时能调用处理函数。等有文件描述符 ready 后,在 select 返回退出之前,kernel 还需要再次遍历描述符集合,将设置的这些处理函数拆除再返回。
- 有惊群问题。假设一个文件描述符 123 被多个进程或线程注册在自己的 select 描述符集合内,当这个文件描述符 ready 后会将所有监听它的进程或线程全部唤醒。
- 无法动态添加描述符,比如一个线程已经在执行 select 了,突然想写数据到某个新描述符上,就只能等前一个 select 返回后重新设置 FD Set 重新执行 select。
poll
Linux manual page:poll(2)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
POLL(2) Linux Programmer's Manual POLL(2)
NAME top
poll, ppoll - wait for some event on a file descriptor
SYNOPSIS top
#include <poll.h>
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
#define _GNU_SOURCE /* See feature_test_macros(7) */
#include <signal.h>
#include <poll.h>
int ppoll(struct pollfd *fds, nfds_t nfds,
const struct timespec *tmo_p, const sigset_t *sigmask);
poll提供的功能与select类似,不过在处理流设备时,它能够提供额外的信息。
poll没有使用select中的fd_set(底层是bitmap),而是采用的pollfds。
有数据时,会置位pollfd revents字段,然后poll方法返回。返回后遍历pollfds,判读发生的事件(然后恢复pollfd revents,可以重用pollfds)。
- 解决了select的1024的限制;
- 解决了fd_set不能重用的问题;
但是fds用户态到内核态切换+用户态处理数据需遍历整个fds没有解决
函数定义
#include <poll.h>
int poll(struct pollfd *fdarray, unsigned long nfds, int timeout);
// 返回:若有就绪描述符则为其数目,若超时则为0,若出错则为-1
第一个参数是指向一个结构数组第一个元素的指针。每个数组元素都是一个pollfd结构,用于指定测试某个给定描述符fd的条件。
struct pollfd {
int fd; /* descriptor to check */
short events; /* events of interest on fd */
short revents; /* events that occurred on fd */
};
用于指定events标志以及测试revents标志的一些常值
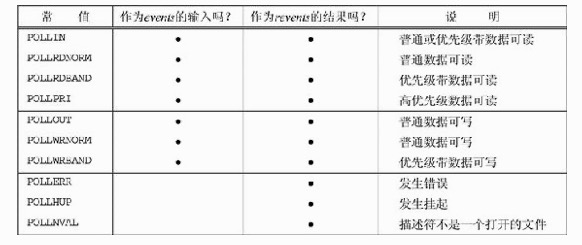
看到 fds 还是关注的描述符列表,只是在 poll 里更先进一些,将 events 和 reevents 分开了,所以如果关注的 events 没有发生变化就可以重用 fds,poll 只修改 revents 不会动 events。再有 fds 是个数组,不是 fds_set,没有了上限。
相对于 select 来说,poll 解决了 fds 长度上限问题,解决了监听描述符无法复用问题,但仍然需要在 poll 返回后遍历 fds 去找 ready 的描述符,也需要清理 ready 描述符对应的 revents,Kernel 也同样是每次 poll 调用需要去遍历 fds 注册监听,poll 返回时候拆除监听,也仍然有与 select 一样的惊群问题,也有无法动态修改描述符的问题。
epoll
在《Unix网络编程》第三版(2003年)还没有介绍 epoll,因为那个时代epoll还没有出现,书中只介绍了 select和poll
Linux manual page:epoll(7)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
EPOLL(7) Linux Programmer's Manual EPOLL(7)
NAME top
epoll - I/O event notification facility
SYNOPSIS top
#include <sys/epoll.h>
DESCRIPTION top
The epoll API performs a similar task to poll(2): monitoring multiple
file descriptors to see if I/O is possible on any of them. The epoll
API can be used either as an edge-triggered or a level-triggered
interface and scales well to large numbers of watched file
descriptors.
The central concept of the epoll API is the epoll instance, an in-
kernel data structure which, from a user-space perspective, can be
considered as a container for two lists:
· The interest list (sometimes also called the epoll set): the set of
file descriptors that the process has registered an interest in
monitoring.
· The ready list: the set of file descriptors that are "ready" for
I/O. The ready list is a subset of (or, more precisely, a set of
references to) the file descriptors in the interest list. The
ready list is dynamically populated by the kernel as a result of
I/O activity on those file descriptors.
epoll是Linux内核的可扩展I/O事件通知机制。设计目的旨在取代既有POSIX select(2)与poll(2)系统函数,让需要大量操作文件描述符的程序得以发挥更优异的性能(举例来说:旧有的系统函数所花费的时间复杂度为O(n),epoll的时间复杂度O(log n))。epoll 实现的功能与 poll 类似,都是监听多个文件描述符上的事件。
epoll与FreeBSD的kqueue类似,底层都是由可配置的操作系统内核对象建构而成,并以文件描述符(file descriptor)的形式呈现于用户空间。epoll 通过使用红黑树(RB-tree)搜索被监视的文件描述符(file descriptor)。
在 epoll 实例上注册事件时,epoll 会将该事件添加到 epoll 实例的红黑树上并注册一个回调函数,当事件发生时会将事件添加到就绪链表中。
pluser 的一段场景描述可以很好的交代 epoll 背景及原理
设想一个场景:有100万用户同时与一个进程保持着TCP连接,而每一时刻只有几十个或几百个TCP连接是活跃的(接收TCP包),也就是说在每一时刻进程只需要处理这100万连接中的一小部分连接。那么,如何才能高效的处理这种场景呢?进程是否在每次询问操作系统收集有事件发生的TCP连接时,把这100万个连接告诉操作系统,然后由操作系统找出其中有事件发生的几百个连接呢?实际上,在Linux2.4版本以前,那时的select或者poll事件驱动方式是这样做的。
这里有个非常明显的问题,即在某一时刻,进程收集有事件的连接时,其实这100万连接中的大部分都是没有事件发生的。因此如果每次收集事件时,都把100万连接的套接字传给操作系统(这首先是用户态内存到内核态内存的大量复制),而由操作系统内核寻找这些连接上有没有未处理的事件,将会是巨大的资源浪费,然后select和poll就是这样做的,因此它们最多只能处理几千个并发连接。而epoll不这样做,它在Linux内核中申请了一个简易的文件系统,把原先的一个select或poll调用分成了3部分:
(1)调用epoll_create建立一个epoll对象(在epoll文件系统中给这个句柄分配资源); (2)调用epoll_ctl向epoll对象中添加这100万个连接的套接字; (3)调用epoll_wait收集发生事件的连接;
这样只需要在进程启动时建立1个epoll对象,并在需要的时候向它添加或删除连接就可以了,因此,在实际收集事件时,epoll_wait的效率就会非常高,因为调用epoll_wait时并没有向它传递这100万个连接,内核也不需要去遍历全部的连接。
epoll 提供以下系统调用来创建和管理实例
- epoll_create(2) creates a new epoll instance and returns a file descriptor referring to that instance. (The more recent epoll_create1(2) extends the functionality of epoll_create(2).) 该接口是在内核区创建一个epoll相关的一些列结构,并且将一个句柄fd返回给用户态,后续的操作都是基于此fd的,参数size是告诉内核这个结构的元素的大小,类似于stl的vector动态数组,如果size不合适会涉及复制扩容,不过貌似4.1.2内核之后size已经没有太大用途了;
- Interest in particular file descriptors is then registered via epoll_ctl(2), which adds items to the interest list of the epoll instance. epoll_ctl该接口是将fd添加/删除于epoll_create返回的epfd中,其中epoll_event是用户态和内核态交互的结构,定义了用户态关心的事件类型和触发时数据的载体epoll_data;
- epoll_wait(2) waits for I/O events, blocking the calling thread if no events are currently available. (This system call can be thought of as fetching items from the ready list of the epoll instance.) epoll_wait该接口是阻塞等待内核返回的可读写事件,epfd还是epoll_create的返回值,events是个结构体数组指针存储epoll_event,也就是将内核返回的待处理epoll_event结构都存储下来,maxevents告诉内核本次返回的最大fd数量,这个和events指向的数组是相关的;
使用现实中的例子进行通俗解释:
- epoll_create场景:大学开学第一周,你作为班长需要帮全班同学领取相关物品,你在学生处告诉工作人员,我是xx学院xx专业xx班的班长,这时工作人员确定你的身份并且给了你凭证,后面办的事情都需要用到(也就是调用epoll_create向内核申请了epfd结构,内核返回了epfd句柄给你使用);
- epoll_ctl场景:你拿着凭证在办事大厅开始办事,分拣办公室工作人员说班长你把所有需要办理事情的同学的学生册和需要办理的事情都记录下来吧,于是班长开始在每个学生手册单独写对应需要办的事情:李明需要开实验室权限、孙大熊需要办游泳卡……就这样班长一股脑写完并交给了工作人员(也就是告诉内核哪些fd需要做哪些操作);
- epoll_wait场景:你拿着凭证在领取办公室门前等着,这时候广播喊xx班长你们班孙大熊的游泳卡办好了速来领取、李明实验室权限卡办好了速来取….还有同学的事情没办好,所以班长只能继续(也就是调用epoll_wait等待内核反馈的可读写事件发生并处理);
epoll官方demo,注意 epoll_create1、epoll_ctl、epoll_wait 及 epollfd的使用
#define MAX_EVENTS 10
struct epoll_event ev, events[MAX_EVENTS];
int listen_sock, conn_sock, nfds, epollfd;
/* Code to set up listening socket, 'listen_sock',
(socket(), bind(), listen()) omitted */
epollfd = epoll_create1(0);
if (epollfd == -1) {
perror("epoll_create1");
exit(EXIT_FAILURE);
}
ev.events = EPOLLIN;
ev.data.fd = listen_sock;
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, listen_sock, &ev) == -1) {
perror("epoll_ctl: listen_sock");
exit(EXIT_FAILURE);
}
for (;;) {
nfds = epoll_wait(epollfd, events, MAX_EVENTS, -1);
if (nfds == -1) {
perror("epoll_wait");
exit(EXIT_FAILURE);
}
for (n = 0; n < nfds; ++n) {
if (events[n].data.fd == listen_sock) {
conn_sock = accept(listen_sock,
(struct sockaddr *) &addr, &addrlen);
if (conn_sock == -1) {
perror("accept");
exit(EXIT_FAILURE);
}
setnonblocking(conn_sock);
ev.events = EPOLLIN | EPOLLET;
ev.data.fd = conn_sock;
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, conn_sock,
&ev) == -1) {
perror("epoll_ctl: conn_sock");
exit(EXIT_FAILURE);
}
} else {
do_use_fd(events[n].data.fd);
}
}
}
Eage-Trigger and Level-Trigger
epoll 有两种工作方式:LT(水平触发) 和 ET(边缘触发)。LT 即只要有事件就通知,而 ET 则只有状态变化时才会通知。
- LT 状态下,只要有通知,所有监听这个 socket 的线程都会被唤醒。
- ET 状态下,内核只会通知一次(一个线程),因此无论是accept()、read()还是write()都要循环操作到底层返回EAGAIN为止,否则下次的 epoll_wait 不会返回余下的数据,会丢掉事件。如果ET模式不是非阻塞的,那这个一直读或一直写势必会在最后一次阻塞。
但是 ET 也会有竞争问题:线程A的epoll_wait()返回后,线程 A 不断的调用accept()处理连接请求,当内核的accept queue队列中的请求恰好处理完时候,内核会重新将该 socket 置为不可读状态,以便可以重新被触发;此时如果新来了一个连接,那么另外一个线程 B 可能被唤醒,然后执行accept()操作,不过此时之前的线程 A 还需要重新再执行一次accept()以确认accept queue已经被处理完了,此时如果线程A成功accept的话,线程 B 就被惊醒了(线程 B 没有accept成功)。
这两种触发模式在 epoll(7) - Linux manual page 文档中举了一个挺好的例子,在这里大致记录一下。假设场景如下:
- 一个 Socket 注册在 epoll FD 上,监听它读事件;
- Socket 另一端发送了 2 KB 数据到这个 Socket;
- epoll_wait 返回,并带着这个 Socket 的 FD 说它读 Ready;
- Socket 的 Reader 只从 Socket 读了 1 KB 的数据;
- 再次执行 epoll_wait
如果这个 Socket 注册在 epoll FD 上时带着 EPOLLET flag,即 ET 模式下,即使 Socket 还有 1 KB 数据没读,第五步 epoll_wait 执行时也不会立即返回,会一直阻塞下去直到再有新数据到达这个 Socket。因为这个 Socket 上的数据一直没有读完,其 Ready 状态在上一次触发 epoll_wait 返回后一直没被清理。需要等这个 Socket 上所有可读的数据全部被读干净,read() 操作返回 EAGAIN 后,再次执行 epoll_wait 如果再有新数据到达 Socket,epoll_wait 才会立即因为 Socket 读 Ready 而返回。
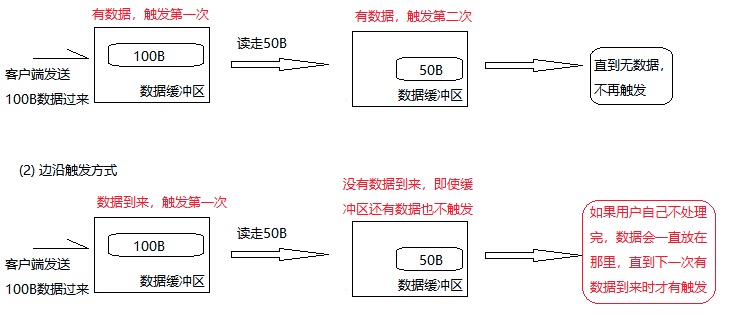
而如果使用的是 LT 模式,Socket 还剩 1 KB 数据没读,第五步执行 epoll_wait 后它也会带着这个 Socket 的 FD 立即返回,event 列表内会记录这个 Socket 读 Ready。
这里是以读数据为例,但实际上比如写数据,执行 accept() 等都适用。此外,两者还在唤醒线程上有区别。比如一个进程通过 fork() 方式继承了父进程的 epoll FD,上面注册了一些监听的 FD。当某个 FD Ready 时,如果是 ET 模式下则只会唤醒父子进程中的一个,如果是 LT 模式,则会将父子进程都唤醒。
需要补充说明的是,ET 模式下如果数据是分好几个部分到来的,则即使是处于读 Ready 状态且 Socket 还未读空情况下,每个新到达的数据部分都会触发一次 epoll_wait 返回,除非 Socket 的 FD 在注册到 epoll FD 的时候设置 EPOLLONESHOT flag,这样 Socket 只要触发过一次 epoll_wait 返回后不管再有多少数据到来,Socket 有没有读空,都不会再触发 epoll_wait 返回,必须主动带着 EPOLL_CTL_MOD 再执行一次 epoll_ctl 把 Socket 的 FD 重新设置到 epoll 的 FD 上,这个 Socket 才会触发下一次读 Ready 让 epoll_wait 返回。
Edge Trigger 有什么好处呢?我理解一个是多线程执行 epoll_wait 时能不需要把所有线程都唤醒,再有单线程情况下也能减少 epoll_wait 被唤醒次数,可以实现尽量均匀的为所有 Socket 执行 IO 操作。比如有 1000 个 Socket 被监听,其中有一个 Socket 发来数据量特别大,其它 Socket 发来的数据都很少,如果是 Level Trigger,处理线程必须把数据量特别大的这个 Socket 上数据全处理干净,epoll_wait 才能阻塞住,不然每次执行都会立即返回。但 Edge Trigger 下,我可以只从数据量大的 Socket 读一点数据并记录下这个 Socket 还有数据没读完,之后带着 timeout 去执行 epoll_wait ,返回后可以先处理别的 Socket 上的数据,再回头处理数据量大的那个 Socket 的数据,从而公平的执行所有 Socket 上的 IO 操作。
epoll 原理
红黑树节点定义
#ifndef _LINUX_RBTREE_H
#define _LINUX_RBTREE_H
#include <linux/kernel.h>
#include <linux/stddef.h>
#include <linux/rcupdate.h>
struct rb_node {
unsigned long __rb_parent_color;
struct rb_node *rb_right;
struct rb_node *rb_left;
} __attribute__((aligned(sizeof(long))));
/* The alignment might seem pointless, but allegedly CRIS needs it */
struct rb_root {
struct rb_node *rb_node;
};
epitem定义
struct epitem {
struct rb_node rbn;
struct list_head rdllink;
struct epitem *next;
struct epoll_filefd ffd;
int nwait;
struct list_head pwqlist;
struct eventpoll *ep;
struct list_head fllink;
struct epoll_event event;
}
eventpoll定义
struct eventpoll {
spin_lock_t lock;
struct mutex mtx;
wait_queue_head_t wq;
wait_queue_head_t poll_wait;
struct list_head rdllist; //就绪链表
struct rb_root rbr; //红黑树根节点
struct epitem *ovflist;
}
epoll的设计:
- epoll在Linux内核中构建了一个文件系统,该文件系统采用红黑树来构建,红黑树在增加和删除上面的效率极高,因此是epoll高效的原因之一。
- epoll红黑树上采用事件异步唤醒,内核监听I/O,事件发生后内核搜索红黑树并将对应节点数据放入异步唤醒的事件队列中。
- epoll的数据从用户空间到内核空间采用mmap存储I/O映射来加速。该方法是目前Linux进程间通信中传递最快,消耗最小,传递数据过程不涉及系统调用的方法。
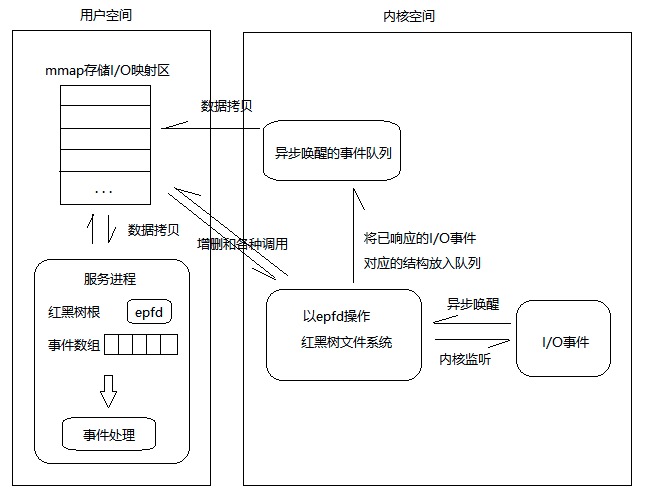
Linux的I/O效率不会随着文件描述符数量的增加而线性下降。较之于select/poll,当处于一个高并发时(例如10万,100万)。在如此庞大的socket集合中,任一时间里其实只有部分的socket是“活跃”的。select/poll的处理方式是,对用如此庞大的集合进行线性扫描并对有事件发生的socket进行处理,这将极大的浪费CPU资源。因此epoll的改进是,由于I/O事件发生,内核将活跃的socket放入队列并交给mmap加速到用户空间,程序拿到的集合是处于活跃的socket集合,而不是所有socket集合。
使用mmap加速内核与用户空间的消息传递。select/poll采用的方式是,将所有要监听的文件描述符集合拷贝到内核空间(用户态到内核态切换)。接着内核对集合进行轮询检测,当有事件发生时,内核从中集合并将集合复制到用户空间。 再看看epoll怎么做的,内核与程序共用一块内存,请看epoll总体描述01这幅图,用户与mmap加速区进行数据交互不涉及权限的切换(用户态到内核态,内核态到用户态)。内核对于处于非内核空间的内存有权限进行读取。
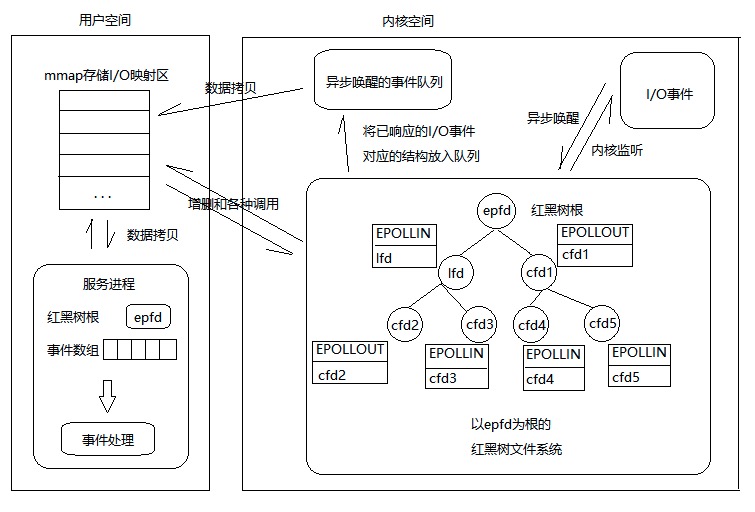
使用epoll接口的一般操作流程为:
- 使用epoll_create()创建一个epoll对象,该对象与epfd关联,后续操作使用epfd来使用这个epoll对象,这个epoll对象才是红黑树,epfd作为描述符只是能关联而已。
- 调用epoll_ctl()向epoll对象中进行增加、删除等操作。
- 调用epoll_wait()可以阻塞(或非阻塞或定时) 返回待处理的事件集合。
- 处理事件。
/*
* -[ 一般epoll接口使用描述01 ]-
*/
int main(void)
{
/*
* 此处省略网络编程常用初始化方式(从申请到最后listen)
* 并且部分的错误处理省略,我会在后面放上所有的源码,这里只放重要步骤
* 部分初始化也没写
*/
// [1] 创建一个epoll对象
ep_fd = epoll_create(OPEN_MAX); /* 创建epoll模型,ep_fd指向红黑树根节点 */
listen_ep_event.events = EPOLLIN; /* 指定监听读事件 注意:默认为水平触发LT */
listen_ep_event.data.fd = listen_fd; /* 注意:一般的epoll在这里放fd */
// [2] 将listen_fd和对应的结构体设置到树上
epoll_ctl(ep_fd, EPOLL_CTL_ADD, listen_fd, &listen_ep_event);
while(1) {
// [3] 为server阻塞(默认)监听事件,ep_event是数组,装满足条件后的所有事件结构体
n_ready = epoll_wait(ep_fd, ep_event, OPEN_MAX, -1);
for(i=0; i<n_ready; i++) {
temp_fd = ep_event[i].data.fd;
if(ep_event[i].events & EPOLLIN){
if(temp_fd == listen_fd) { //说明有新连接到来
connect_fd = accept(listen_fd, (struct sockaddr *)&client_socket_addr, &client_socket_len);
// 给即将上树的结构体初始化
temp_ep_event.events = EPOLLIN;
temp_ep_event.data.fd = connect_fd;
// 上树
epoll_ctl(ep_fd, EPOLL_CTL_ADD, connect_fd, &temp_ep_event);
}
else { //cfd有数据到来
n_data = read(temp_fd , buf, sizeof(buf));
if(n_data == 0) { //客户端关闭
epoll_ctl(ep_fd, EPOLL_CTL_DEL, temp_fd, NULL) //下树
close(temp_fd);
}
else if(n_data < 0) {}
do {
//处理数据
}while( (n_data = read(temp_fd , buf, sizeof(buf))) >0 ) ;
}
}
else if(ep_event[i].events & EPOLLOUT){
//处理写事件
}
else if(ep_event[i].events & EPOLLERR) {
//处理异常事件
}
}
}
close(listen_fd);
close(ep_fd);
}
epoll Reactor
将 epoll 设置为非阻塞式和ET模式
在epoll接口使用代码中,我们在该结构体中的联合体上传入的是文件描述符本身,那么epoll模型和epoll接口最本质的区别在于epoll模型中,传入联合体的是一个自定义结构体指针,该结构体的基本结构至少包括
/*
* 注意:用户需要自行开辟空间存放my_events类型的数组,并在每次上树前用epoll_data_t里的ptr指向一个my_events元素。
*/
struct my_events {
int m_fd; //监听的文件描述符
void *m_arg; //泛型参数
void (*call_back)(void *arg); //回调函数
// 此处封装更多的数据内容,例如用户缓冲区、节点状态、节点上树时间等等
};
epoll_wait()返回后,epoll模型将不会采用”epoll接口的一般操作流程”的事件分类处理的办法,而是直接调用事件中对应的回调函数,就像这样
/*
* -[ epoll模型使用描述01 ]-
*/
while(1) {
// 监听红黑树, 1秒没事件满足则返回0
int n_ready = epoll_wait(ep_fd, events, MAX_EVENTS, 1000);
if (n_ready > 0) {
for (i=0; i<n_ready; i++)
events[i].data.ptr->call_back(/* void *arg */);
}
else
/*
* (3) 这里可以做很多很多其他的工作,例如定时清除没读完的不要的数据
* 也可以做点和数据库有关的设置
* 玩大点你在这里搞搞分布式的代码也可以
*/
}
由一般操作流程的改为如下流程
- epoll_create(); // 创建监听红黑树
- epoll_ctl(); // 向书上添加监听fd
- epoll_wait(); // 监听
- 有客户端连接上来—>lfd调用acceptconn()—>将cfd挂载到红黑树上监听其读事件—>
- epoll_wait()返回cfd—>cfd回调recvdata()—>将cfd摘下来监听写事件—>
- epoll_wait()返回cfd—>cfd回调senddata()—>将cfd摘下来监听读事件—>…—>
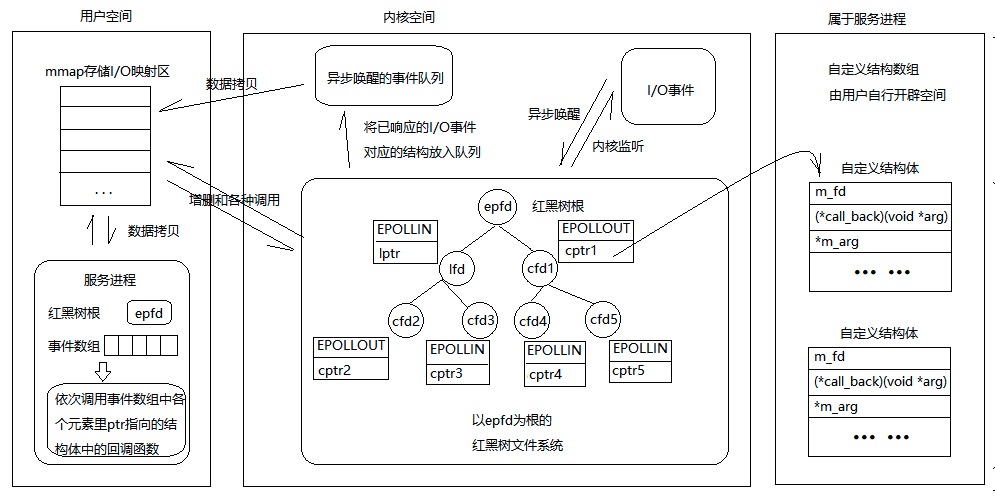
一个简单的示例,功用就是让epoll 监听你有注册的socket,然后当有事件产生时,就可以从epoll_wait 取得相对应的socket 与事件,最后再将此事件执行到对应的event handler。
struct events[10];
// 建立一个 epoll 用 file descriptor
epollfd = epoll_create();
// 注册让 epoll 监听某 socket 的 EPOLLIN 事件(可读取)
epoll_ctl(epollfd, EPOLL_CTL_ADD, socket, EPOLLIN);
while(true){
// 如果 epoll queue 中有事件发生,则会回传产生事件的 socket 与 events。
have_events_fds = epoll_wait( epollfd, events, MAX_EVENTS, -1 );
// 读取每个有产生事件的 socket,並执行对应的 eventHandler。
for(int i=0; i < have_events_fds; i++){
eventHandler(events[n]);
}
}
epoll and Java Selector
Java 的 NIO 提供了一个叫 Selector的类,用于跨平台的实现 Socket Polling,也即 IO 多路复用。比如在 BSD 系统上它背后对应的就是 Kqueue,在 Windows 上对应的是 Select,在 Linux 上对应的是 Level Trigger 的 epoll。Linux 上为什么非要是 Level Trigger 呢?主要是为了跨平台统一,在 Windows 上背后是 Select,它是 Level Trigger 的,那为了同一套代码多处运行,在 Linux 上也只能是 Level Trigger 的,不然使用方式就不同了。
这也是为什么 Netty 自己又为 Linux 单独实现了一套 EpollEventLoop 而不只是提供 NioEventLoop 就完了。因为 Netty 想支持 Edge Trigger,并且还有很多 epoll 专有参数想支持。参看这里 Netty 的维护者的回答:Why native epoll support is introduced in Netty?
Netty’s epoll transport uses epoll edge-triggered while java’s nio library uses level-triggered. Beside this the epoll transport expose configuration options that are not present with java’s nio like TCP_CORK, SO_REUSEPORT and more.
Selector 的使用:
- 先通过 Selector.open() 创建出来 Selector;
- 创建出来 SelectableChannel (可以理解为 Socket),配置 Channel 为 Non-Blocking
- 通过 Channel 下的 register() 接口注册 Channel 到 Selector,注册时可以带上关心的事件比如 OPREAD,OPACCEPT, OP_WRITE 等;
- 调用 Selector 上的 select() 等待有 Channel 上有 Event 产生
- select() 返回后说明有 Channel 有 Event 产生,通过 Selector 获取 SelectionKey 即哪些 Channel 有什么事件产生了;
- 遍历所有获取的 SelectionKey 检查产生了什么事件,是 OPREAD 还是 OPWRITE 等,之后处理 Channel 上的事件;
- 从 select() 返回的 Iterator 中移除处理完的 SelectionKey
可以看到整个使用过程和使用 select, poll, epoll 的过程是能对应起来的。再补充一下,Selector 是通过 SPI (Java Service Provider Interface)来实现不同平台使用不同 Selector 实现的。
epoll and Netty
Netty 对 Linux 的 epoll 接口做了一层封装,封装为 JNI 接口供上层 JVM 来调用。
epoll 优缺点
epoll 优点:
- 监听的描述符没有上限;
- epoll_wait 每次只会返回 Ready 的描述符,不用完整遍历所有被监听的描述符;
- 监听的描述符被注册到 epoll 后会与 epoll 的描述符绑定,维护在内核,不主动通过 epoll_ctl 执行删除不会自动被清理,所以每次执行 epoll_wait 后用户侧不用重新配置监听,Kernel 侧在 epoll_wait 调用前后也不会反复注册和拆除描述符的监听;
- 可以通过 epoll_ctl 动态增减监听的描述符,即使有另一个线程已经在执行 epoll_wait;
- epoll_ctl 在注册监听的时候还能传递自定义的 event_data,一般是传描述符,但应用可以根据自己情况传别的;
- 即使没线程等在 epoll_wait 上,Kernel 因为知道所有被监听的描述符,所以在这些描述符 Ready 时候就能做处理,等下次有线程调用 epoll_wait 时候直接返回。这也帮助 epoll 去实现 IO Edge Trigger,即 IO Ready 时候 Kernel 就标记描述符为 Ready 之后在描述符被读空或写空前不再去监听它,后面详述;
- 多个不同的线程能同时调用 epoll_wait 等在同一个 epoll 描述符上,有描述符 Ready 后它们就去执行。
epoll 缺点:
- epoll_ctl 是个系统调用,每次修改监听事件,增加监听描述符时候都是一次系统调用,并且没有批量操作的方法。比如一口气要监听一万个描述符,要把一万个描述符从监听读改到监听写等就会很耗时,很低效;
- 对于服务器上大量连上又断开的连接处理效率低,即 accept() 执行后生成一个新的描述符需要执行 epoll_ctl 去注册新 Socket 的监听,之后 epoll_wait 又是一次系统调用,如果 Socket 立即断开了 epoll_wait 会立即返回,又需要再用 epoll_ctl 把它删掉;
- 依然有惊群问题,需要配合使用方式避免。
kqueue
FreeBSD随4.1版本引入了kqueue接口。本接口允许进程向内核注册描述所关注kqueue事件的事件过滤器(event filter)。
The kqueue() system call provides a generic method of notifying the user when an event happens or a condition holds, based on the results of small pieces of kernel code termed filters. A kevent is identified by the (ident, filter) pair; there may only be one unique kevent per kqueue.
事件除了与select所关注类似的文件I/O和超时外,还有异步I/O、文件修改通知(例如文件被删除或修改时发出的通知)、进程跟踪(例如进程调用exit或fork时发出的通知)和信号处理。kqueue接口包括如下2个函数和1个宏。
BSD System Calls Manual:KQUEUE(2)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
NAME
kqueue, kevent -- kernel event notification mechanism
LIBRARY
Standard C Library (libc, -lc)
SYNOPSIS
#include <sys/event.h>
int
kqueue(void);
int
kevent(int kq, const struct kevent *changelist, int nchanges,
struct kevent *eventlist, int nevents,
const struct timespec *timeout);
EV_SET(kev, ident, filter, flags, fflags, data, udata);
kqueue函数返回一个新的kqueue描述符,用于后续的kevent调用中。kevent函数既用于注册所关注的事件,也用于确定是否有所关注事件发生。changelist和nchanges这两个参数给出对所关注事件做出的更改,若无更改则分别取值NULL和0。如果nchanges不为0,kevent函数就执行changelist数组中所请求的每个事件过滤器更改。其条件已经触发的任何事件(包括刚在changelist中增设的那些事件)由kevent函数通过eventlist参数返回,它指向一个由nevents个元素构成的kevent结构数组。kevent函数在eventlist中返回的事件数目作为函数返回值返回,0表示发生超时。超时通过timeout参数设置,其处理类似select:NULL阻塞进程,非0值timespec指定明确的超时值,0值timespec执行非阻塞事件检查。注意,kevent使用的timespec结构不同于select使用的timeval结构,前者的分辨率为纳秒,后者的分辨率为微秒。
kevent结构在头文件<sys/event.h>中定义:
struct kevent {
uintptr_t ident; /* identifier for this event */
short filter; /* filter for event */
u_short flags; /* action flags for kqueue */
u_int fflags; /* filter flag value */
int64_t data; /* filter data value */
void *udata; /* opaque user data identifier */
uint64_t ext[4]; /* extensions */
};
其中flags成员在调用时指定过滤器更改行为,在返回时额外给出条件

filter成员指定的过滤器类型
| filter | 说明 |
|---|---|
| EVFILT_READ | 描述符可读,类似 select。 Takes a descriptor as the identifier, and returns whenever there is data available to read. The behavior of the filter is slightly different depending on the descriptor type. |
| EVFILT_WRITE | 描述符可写,类似 select。 Takes a descriptor as the identifier, and returns whenever it is possible to write to the descriptor. |
| EVFILT_EMPTY | Takes a descriptor as the identifier, and returns whenever there is no remaining data in the write buffer. |
| EVFILT_AIO | 异步I/O事件。Events for this filter are not registered with kevent() directly but are registered via the aio_sigevent member of an asynchronous I/O request when it is scheduled via an asynchronous I/O system call such as aio_read(). The filter returns under the same conditions as aio_error(). For more details on this filter see sigevent(3) and aio(4). |
| EVFILT_VNODE | 文件修改和删除事件。Takes a file descriptor as the identifier and the events to watch for in fflags, and returns when one or more of the requested events occurs on the descriptor. |
| EVFILT_PROC | 进程exit、fork或者exec事件。Takes the process ID to monitor as the identifier and the events to watch for in fflags, and returns when the process performs one or more of the requested events. If a process can normally see another process, it can attach an event to it. |
| EVFILT_PROCDESC | Takes the process descriptor created by pdfork(2) to monitor as the identifier and the events to watch for in fflags, and returns when the associated process performs one or more of the requested events. |
| EVFILT_SIGNAL | 收到信号。Takes the signal number to monitor as the identifier and returns when the given signal is delivered to the process. This coexists with the signal() and sigaction() facilities, and has a lower precedence. The filter will record all attempts to deliver a signal to a process, even if the signal has been marked as SIG_IGN, except for the SIGCHLD signal, which, if ignored, will not be recorded by the filter. Event notification happens after normal signal delivery processing. data returns the number of times the signal has occurred since the last call to kevent(). |
| EVFILT_TIMER | 周期性或者一次性的定时器。Establishes an arbitrary timer identified by ident. When adding a timer, data specifies the moment to fire the timer (for NOTE_ABSTIME) or the timeout period. The timer will be periodic unless EV_ONESHOT or NOTE_ABSTIME is specified. On return, data contains the number of times the timeout has expired since the last call to kevent(). For non-monotonic timers, this filter automatically sets the EV_CLEAR flag internally. |
| EVFILT_USER | Establishes a user event identified by ident which is not associated with any kernel mechanism but is triggered by user level code. |
kqueue 跟 epoll 有些类似,使用方法上很相近。但 kqueue 总体上要高级很多。首先是看到 kevent 有 changelist 参数用于传递关心的 event,nchanges 用于传递 changelist 的大小。eventlist 用于存放当有事件产生后,将产生的事件放在这里。nevents 用于传递 eventlist 大小。timeout 就是超时时间。
这里 kqueue 高级的地方在于,它监听的不一定非要是 Socket,不一定非要是文件,可以是一系列事件,所以 struct kevent 内参数叫 filter,用于过滤出关心的事件。它可以去监听非文件,比如 Signal,Timer,甚至进程。可以实现比如监听某个进程退出。对于磁盘上的普通文件 kqueue 也支持的更好,比如可以在某个文件数据加载到内存后触发 event,从而可以真正 non-blocking 的读文件。而 epoll 去监听普通磁盘文件时就认为文件一定是 Ready 的,但是实际读取的时候如果文件数据不在内存缓存中的话 read() 还是会阻塞住等待数据从磁盘读出来。
可以说 kqueue 有 epoll 的所有优点,甚至还能通过 changelist 一口气注册多个关心的 event,不需要像 epoll 那样每次调用 epoll_ctl 去配置。当然还有上面提到的,因为接口更抽象,能监听的事情更多。但是它也有 epoll 的惊群问题,也需要在使用时候通过配置参数等方式避免。
对比 epoll 和 kqueue 的性能的话,一般认为 kqueue 性能要好一些,但主要原因只是因为 kqueue 支持一口气注册一组 event,能减少系统调用次数。另外 kqueue 没有 Edge Trigger,但能通过 EV_CLEAR 参数实现 Edge Trigger 语义。