来源
在传统体系结构中,相同的数据模型用于查询和更新数据库。这很简单,并且对于基本的CRUD操作非常有效。但是,在更复杂的应用程序中,此方法可能变得复杂。例如,在读取端,应用程序可以执行许多不同的查询,返回具有不同形状的数据传输对象(DTO)。对象映射可能变得复杂。在写方面,模型可以实现复杂的验证和业务逻辑。结果,您最终可能会得到一个过于复杂的模型,而该模型做的太多了。
读取和写入工作负载通常是不对称的,对性能和规模的要求非常不同。
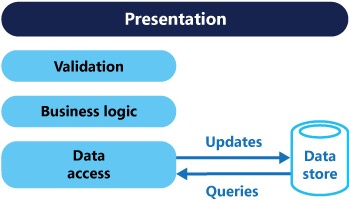
- 数据的读取和写入表示形式之间通常会出现不匹配,例如,即使操作中不需要它们,也必须正确更新其他列或属性。
- 在同一组数据上并行执行操作时,可能会发生数据争用。
- 由于数据存储和数据访问层上的负载以及检索信息所需的查询的复杂性,传统方法可能会对性能产生负面影响。
- 管理安全性和权限可能会变得很复杂,因为每个实体都受到读和写操作的约束,这可能会在错误的上下文中公开数据。
CQRS使用命令更新数据和查询读取数据将读取和写入分离到不同的模型中。
概念
CQS
CQS 模式
在代码实现层面,一个设计良好的方法需要将命令与查询分离,这就是命令查询分离(Command Query Separation,CQS)模式。提出该模式的 Bertrand Meyer 认为:
一个方法要么是执行某种动作的命令,要么是返回数据的查询,而不能两者皆是。换句话说,问题不应该对答案进行修改。更正式的解释是,一个方法只有在具有引用透明(referentially transparent)时才能返回数据,此时该方法不会产生副作用。
It states that every method should either be a command that performs an action, or a query that returns data to the caller, but not both. In other words, Asking a question should not change the answer. More formally, methods should return a value only if they are referentially transparent and hence possess no side effects.
CQRS
CQRS 代表命令查询责任隔离。其核心思想是,您可以使用与用于读取信息的模型不同的模型来更新信息。 by Martin Fowler
CQRS stands for Command Query Responsibility Segregation.
At its heart is the notion that you can use a different model to update information than the model you use to read information.
命令查询责任隔离(CQRS)通过使用单独的 Query 和 Command 对象分别检索和修改数据来应用CQS原理。 By wiki
Command query responsibility segregation (CQRS) applies the CQS principle by using separate Query and Command objects to retrieve and modify data, respectively.
架构
模式的采用可以从现有代码开始逐步应用。为了说明这一点,我们将使用四个可以增量使用的阶段,或者开发人员可以直接从阶段0进入阶段3,而无需考虑其他阶段:
- 阶段0:典型的应用程序数据访问
- 阶段1:单独的读写API
- 阶段2:单独的读写模型
- 阶段3:单独的读写数据库
典型应用数据访问
域模型具有一个API,该API至少使客户端能够对模型中的域对象执行CRUD任务。
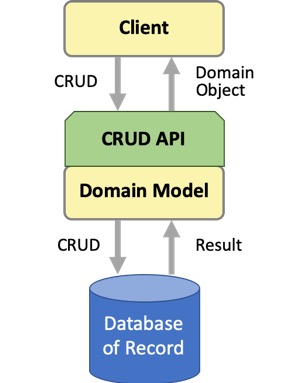
该领域模型是数据库文件或记录的对象表示。它由代表单个文档或记录的域对象以及用于管理和使用它们的业务逻辑组成。域驱动设计(DDD)将这些域对象建模为实体(“具有在时间和不同表示形式下运行的独特身份的对象”)和聚合(“可被视为单个单元的域对象集群”);聚合根维护整个聚合的完整性。
单独的读写API
应用CQRS模式的第一步也是最明显的步骤是将CRUD API分为单独的读取和写入API。该图显示了与以前相同的域模型,但是其单个CRUD API被分为检索和修改API。
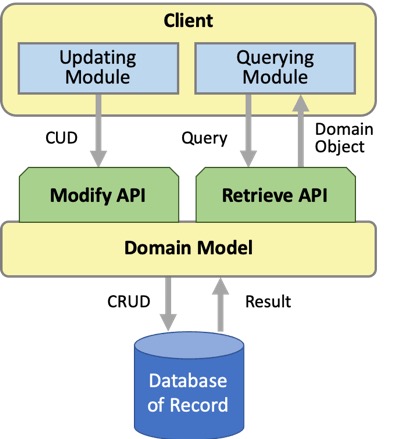
这两个API共享现有的域模型,但将行为分开:
- 读取:检索API用于读取域模型中对象的现有状态,而不更改该状态。API将域状态视为只读。
- 写:修改API用于更改域模型中的对象。使用CUD任务进行更改:创建新的域对象,更新现有域对象的状态,以及删除不再需要的对象。此API中的操作不返回结果值,它们返回成功(ack或void)或失败(nak或引发异常)。创建操作可能会返回实体键的主键,该键可以由域模型或在数据源中生成。
API的这种分离是命令查询分离(CQS)模式的一种应用程序,该模式表示可以清楚地将状态改变的方法与不改变状态的方法分开。为此,对象的每个方法都可以属于以下两种类别之一(但不能同时属于两种):
- 查询:返回结果。不会更改系统状态,也不会引起任何更改状态的副作用。
- 命令(又名修饰符或变异符):更改系统的状态。不返回值,仅表示成功或失败。
使用这种方法,域模型的工作原理相同,并且提供对数据的访问与以前相同。更改的是使用域模型的API。尽管较高级别的操作以前可能既更改了应用程序的状态又返回了该状态的一部分,但现在将每个此类操作重新设计为仅执行一个操作或另一个操作。
此阶段取决于域模型是否能够实现检索和修改API。单个域模型要求检索和修改行为具有相似的相应实现。为了使它们独立发展,将需要使用单独的读取和写入模型来实现这两个API。
分开的读写模型
应用CQRS模式的第二步是将域模型拆分为单独的读取和写入模型。这不仅改变了用于访问域功能的API,而且还改变了该功能的结构和实现方式的设计。该图显示了域模型成为处理域对象更改的写模型的基础,以及用于访问应用程序状态的单独的读模型。
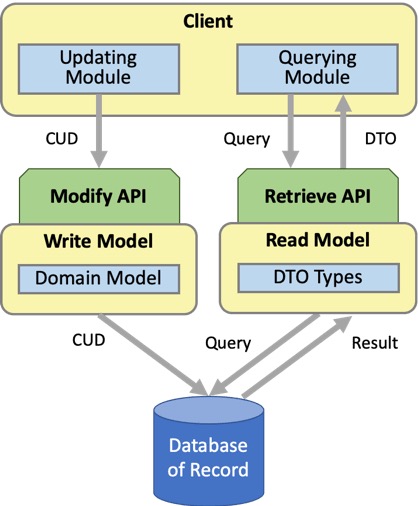
读模型实现检索API,写模型实现修改API。现在,该应用程序不仅包含用于查询和更新域对象的单独的API,而且还具有单独的业务功能。读取业务功能和写入业务功能都共享同一数据库。
通过专门使域模型专注于在更改域对象的状态时保持其有效结构并应用任何业务规则来实现写模型。
同时,将返回域对象的责任转移到单独的读取模型。读取模型定义了专门为模型设计的数据传输对象(DTO),以仅在客户机认为方便的结构中返回客户机所需的数据。
独立的读写数据库
应用CQRS模式的第三步-实现了完整的CQRS模式解决方案-将记录数据库拆分为单独的读写数据库。此图显示了写模型和读模型,它们各自由其数据库支持。总体解决方案包括两个主要部分:支持更新数据的写入解决方案和支持查询数据的读取解决方案。这两个部分通过事件总线连接。
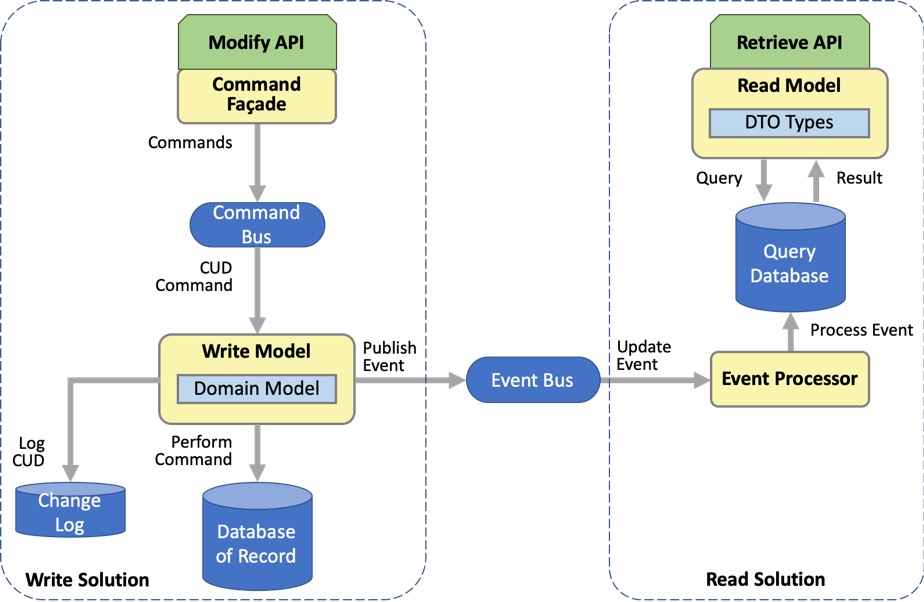
写模型具有自己的读/写数据库,读模型具有自己的只读数据库。读/写数据库仍充当记录数据库(数据真相的唯一来源),但通常仅用于写操作:主要用于写入,很少读取。读取被卸载到一个单独的读取数据库中,该数据库包含相同的数据,但它是只读的。
查询数据库实际上是记录数据库的缓存,具有缓存模式的所有继承优点和复杂性。查询数据库包含记录数据库中数据的副本,该副本的结构和分段结构便于用户使用检索API进行访问。作为副本,需要开销以保持副本与原始文档中的更改同步。此同步过程中的延迟会创建最终的一致性,在此期间数据副本将过时。
单独的数据库支持单独的读写模型以及它们各自的检索和修改API,以真正独立地发展。读取模型或写入模型的实现不仅可以更改而无需更改其他实现,而且可以独立更改每个存储数据的方式。
独立的读写数据库映射到领域驱动概念
根据命令操作的特性以及质量属性的要求,酌情考虑引入命令总线、事件总线以及事件存储。遵循 CQRS 模式的架构如下图所示。by 张逸

注意
在某些情况下,这种分离可能很有价值,但请注意,对于大多数系统,CQRS会增加风险。by Martin Fowler
For some situations, this separation can be valuable, but beware that for most systems CQRS adds risky complexity.
实施此模式的一些挑战包括:
- 复杂性。CQRS的基本思想很简单。但这可能导致更复杂的应用程序设计,特别是如果它们包含事件源模式。
- 消息传递。尽管CQRS不需要消息传递,但通常使用消息传递来处理命令和发布更新事件。在这种情况下,应用程序必须处理消息失败或重复消息。
- 最终的一致性。如果您将读写数据库分开,则读取的数据可能会过时。必须更新读取模型存储以反映对写入模型存储的更改,并且可能很难检测用户何时基于过时的读取数据发出了请求。
读服务
如何构建读服务,有多种方法
双重写入
解决复杂问题的直接方法。在一次交易中,写入两个目的地。
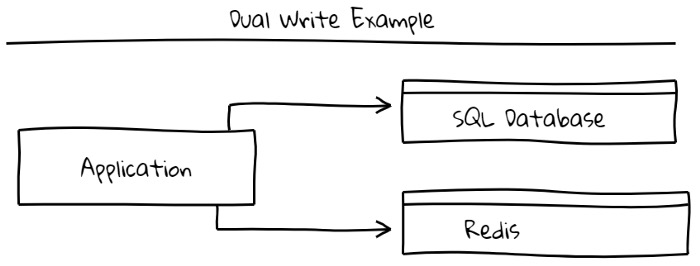
缺点:第一个是如果第二个数据库不支持事务该怎么办。另外,如果第二个服务位于单独的服务或进程中,则由于其本地事务失败,系统将进入不一致状态。
调度写入
后台服务调度程序来轮询数据库中的更改,并将其应用于目标数据库。
缺点:
- 对写数据库施加压力
- 后台调度程序服务本身就是一个失败点
事件驱动方法
写数据库中的状态发生某些更改时,引发一个事件,然后使用者将使用该更改将此更改应用于其基础数据库。
消费者必须订阅才能从中介消息总线(例如RabbitMQ或Kafka)接收指定的事件。
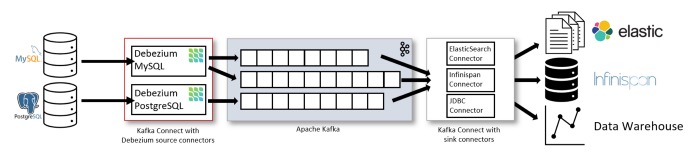
更改数据捕获(CDC)
依靠复制日志充当数据库发出的事件。然后我们可以对它们进行一些流处理。Kafka Connect与Debezium是一项有用的技术,它带来了实施CDC所需的一切。
缺点:
- 将其他系统耦合到我们系统的物理数据模型,并且我们将不得不永远保持公共实体与数据库模型相同