
1 元数据管理
元数据定义
元数据指关于数据的数据。在 Hadoop 生态系统中,元数据有很多种,如下所述。
- 与逻辑数据集有关的元数据。包括以下信息:数据集的位置(比如 HDFS 中的目录或者 HBase 中表的名称)、与数据集有关的模式、数据集的分区与排序特性,以及适用的数据集格式。此类元数据通常存储于独立的元数据仓库中。
- 与 HDFS 文件有关的元数据。包括以下信息:该类文件的权限与属主,以及数据节点上不同数据块的位置。此类信息通常通过 Hadoop NameNode 进行存储和管理。
- 与 HBase 表相关的元数据。包括以下信息:表的名称、相关名称空间、相关属性(如 MAX_FILESIZE、READONLY,等等),以及列簇的名称。此类信息由 HBase 存储和管理。
- 与数据输入和转化有关的元数据。包括以下信息:创建指定数据集的特定用户、数据集的来源、创建数据集花费的时间,以及存在多少条记录,或者加载的数据大小是多少。
- 与数据集统计相关的元数据。包括以下信息:数据集中行的数量、每列中特定值的数量、数据分布的直方图以及最大值和最小值。此类元数据用于不同的工具,这些工具能够利用元数据优化执行计划。它们也能供数据分析师使用,他们可以基于元数据进行快速分析。
元数据存储
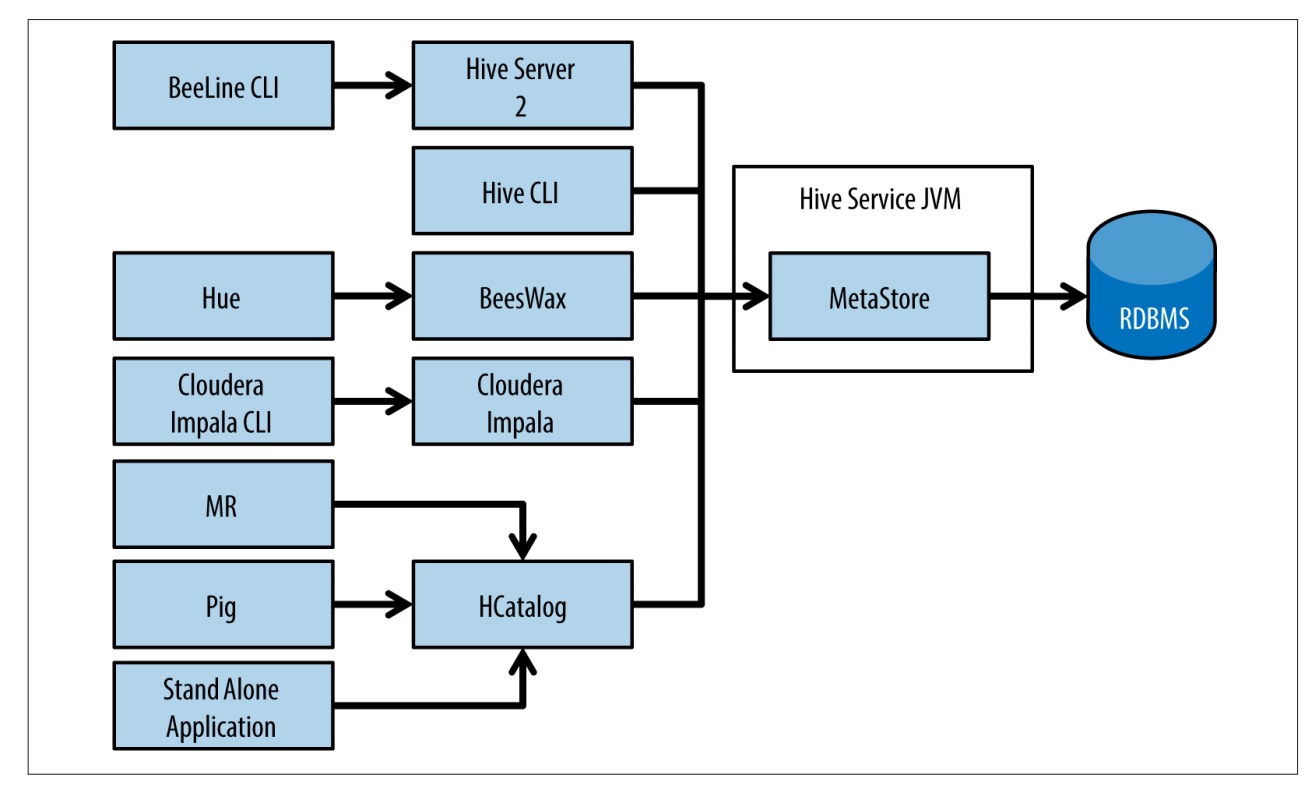
Hadoop 生态系统中第一个开始存储、管理并使用元数据的项目是 Apache Hive 项目。Hive 将元数据存储在一个名为 Hive metastore 的关系型数据库中。
为了能够在 Hive 以外使用 Hive metastore,有一个名为 HCatalog 的项目启动了。现在,HCatalog 成为了 Hive 的一部分。很重要的一点是,HCatalog 能够使其他工具(比如 Pig 和 MapReduce)与 Hive metastore 整合在一起使用。
2 数据处理通用范式
三种数据处理任务,它们也是 Hadoop 上数据处理常见的通用范式,在实现上具有一定的难度。
- 依主键(primary key)移除重复记录(合并去重)。
- 使用数据开窗分析。
- 更新时间序列数据。
模式一:依主键移除重复记录
Hadoop 上的数据经常存在重复的记录,原因如下。
- 数据采集阶段存在重复发送
- 记录更新时的增量数据
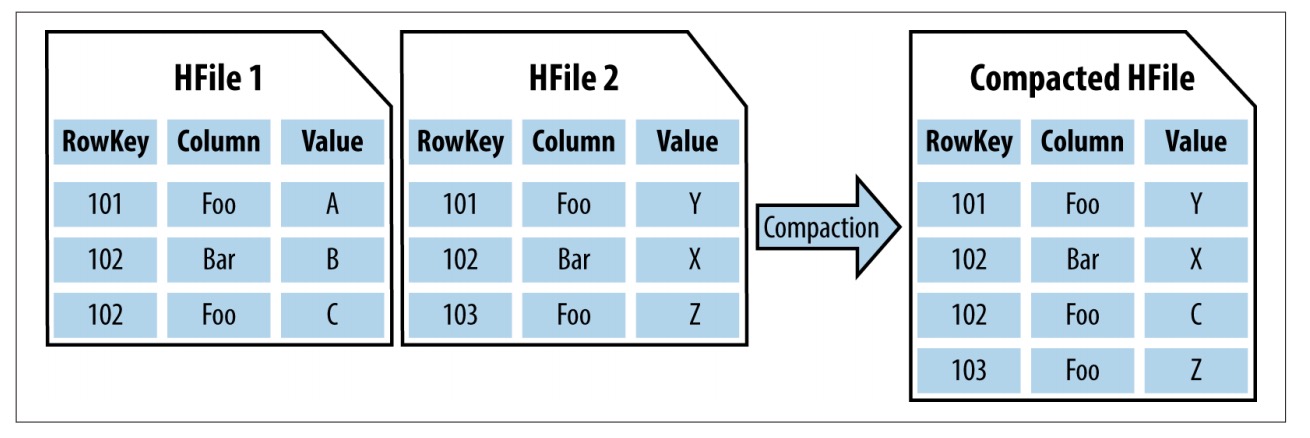
如果熟悉 HBase,你会发现这与 HBase 的工作方式类似。从上层看,HBase 的一个 Region 里有 HFile,其中包含一个键及其对应值。加入新数据时,这里会产生另外一个包含键和值的 HFile。执行合并(compaction)这一清理数据的过程时,HBase 会按键合并,删除重复数据,
SQL 示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
SELECT
A.PRIMARY_KEY,
A.TIME_STAMP,
MAX(A.EVENT_VALUE)
FROM COMPACTION_TABLE A JOIN (
SELECT
PRIMARY_KEY AS P_KEY,
MAX(TIME_STAMP) as TIME_SP
FROM COMPACTION_TABLE
GROUP BY PRIMARY_KEY
) B
WHERE A.PRIMARY_KEY = B.P_KEY AND A.TIME_STAMP = B.TIME_SP
GROUP BY A.PRIMARY_KEY, A.TIME_STAMP
模式二:数据开窗分析
开窗函数(windowing function)支持基于一定的窗口(例如特定的时间片),在有序的事件序列上进行扫描操作。这种处理范式功能强大且用途广泛。

SQL 示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
SELECT
PRIMARY_KEY,
POSITION,
EVENT_VALUE,
CASE
WHEN LEAD_EVENT_VALUE is null or LAG_EVENT_VALUE is null
THEN 'EDGE'
WHEN EVENT_VALUE < LEAD_EVENT_VALUE AND EVENT_VALUE < LAG_EVENT_VALUE
THEN 'VALLEY'
WHEN EVENT_VALUE > LEAD_EVENT_VALUE AND EVENT_VALUE > LAG_EVENT_VALUE
THEN 'PEAK'
ELSE'SLOPE'
END AS POINT_TYPE
FROM
(
SELECT
PRIMARY_KEY,
POSITION,
EVENT_VALUE,
LEAD(EVENT_VALUE, 1, null)
OVER(PARTITION BY PRIMARY_KEY ORDER BY POSITION) AS LEAD_EVENT_VALUE,
LAG(EVENT_VALUE, 1, null)
OVER(PARTITION BY PRIMARY_KEY ORDER BY POSITION) AS LAG_EVENT_VALUE
FROM PEAK_AND_VALLEY_TABLE
) A
SQL 解释
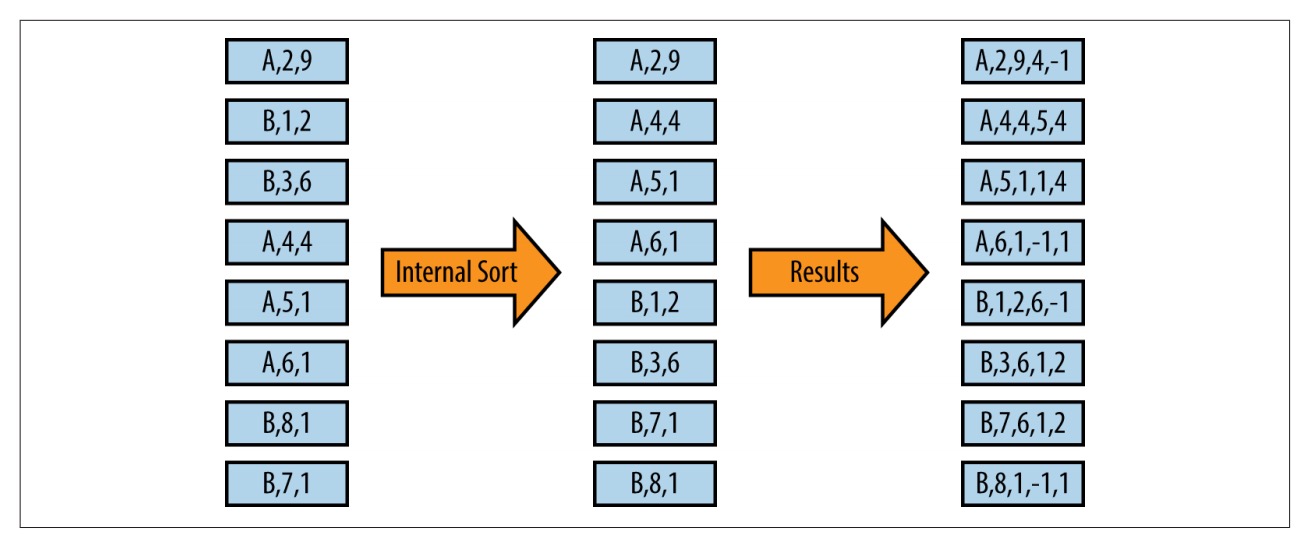
- 在执行了第二步的子查询之后,我们得到了组织好的数据。一条记录中包含了需要的全部信息。我们可以凭这条记录确认以下几种类型:边缘(时间窗口的最左或最右一个点)、高峰(前后的值均比当前值要小)、低谷(前后的值均比当前值要大)、斜坡(前后的值要么都比当前值大,要么都比当前值要小)。
- 在这条子查询中,我们执行数据开窗的逻辑。该查询会将当前值之前和之后的值放入同一行。图中所示就是这条子查询的输入和输出
 (结果列部分数值存疑)
(结果列部分数值存疑)
模式三:基于时间序列的更新
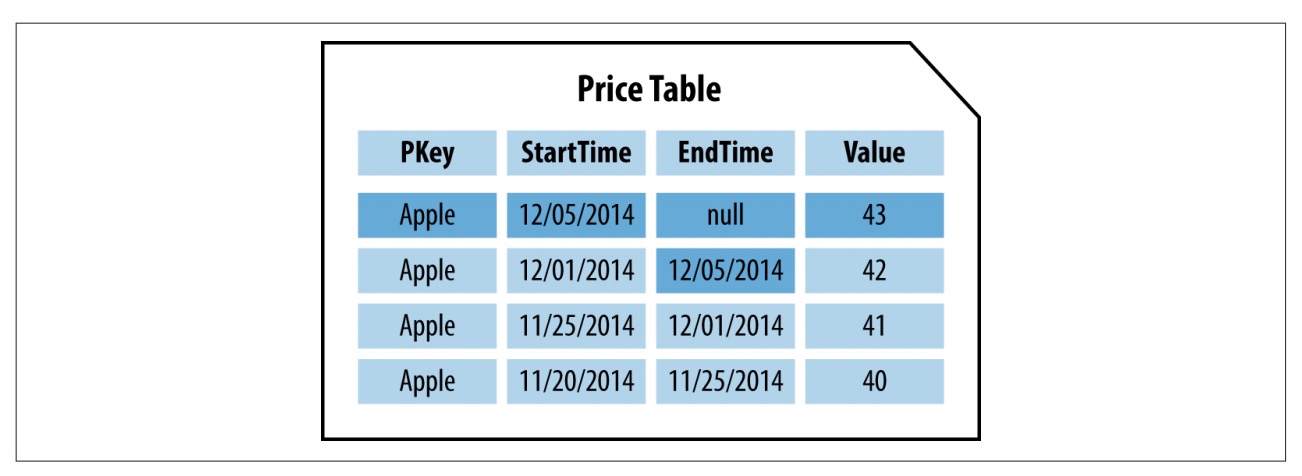
这允许一条记录了解自己的生效时间及失效时间,提供一个实体的信息以及开始和结束的时间

开始和结束时间能够标识一条记录生效的时间区间。如果结束时间为 null,这就意味着该记录的值就是实体的当前值。随之而来的问题是何时更新表。
解决办法
1 利用HBase的版本特性
存储此类信息的一种常见方式就是将记录存成 HBase 的多个版本。HBase 支持对记录的更改以多个版本的形式存储。
2 以记录主键与开始时间作HBase的行键
为了在 HBase 的同一条记录中保存开始和结束时间,我们将创建一个由 RecordKey 和 StartTime 构成的组合键。与之前提到的多版本解决方案不同,这个新方案的记录会有一个列用来存储结束时间。
办法存在的问题:这一方案在大型数据扫描和数据块缓存方面存在一定的问题,但是可以快速地获取某一版本,并在同一行中保存结束时间。值得注意的是,这需要在插入一条记录时外加 get 和 put 操作
3 重写HDFS数据更新整个表
如果放弃使用 HBase,只使用 HDFS 作为实现方案,那么我们需要将所有的数据存储到 HDFS 上。
利用HDFS上的分区存储当前记录和历史记录。在 HDFS 上,这是一个较为明智的做法:将大多数存储当前值的记录放到一个分区里,将其他历史记录放置于另外一个分区中。这样可以只重写最新的版本,而不涉及历史版本。接下来将新记录追加到旧记录所在的分区即可。这样做的最大好处在于执行时间基本固定,不会随历史版本数据的增加而拉长。